Disclaimer: some of the numbers found in this write-up could be inaccurate. They are based on the current understanding of theoretical parts of the protocol itself by the author and are meant to provide a rough overview rather than bindable numbers.
This document mainly serves as a more theoretical analysis of discv5[1] to provide insight on its feasibility in a mobile environment specifically when talking about a messenger like status.
For a rough overview of what some of the technical challenges were / are, the issue vacp2p/specs#32 clearly summarises it.
But from this we can say, there is a need for a decentralized discovery mechanism due to areas with censorship like China, and we have noticed that current methods are problematic for resource restricted devices.
Implications of resource restricted devices
Considering we are focusing on resource restricted devices we need to ask ourselves what the implications of this are, and what constraints that sets for our discovery protocol. There are a few we need to consider.
- battery consumption - constant connections like websockets consume a lot of battery life.
- CPU usage - certain discovery methods may be CPU incentive, slowing an app down and making it unusable.
- bandwidth consumption - a lot of users will be using data plans, the discovery method needs to be efficient in order to accommodate those users without using up significant portions of their data plans.
- short connection windows - the discovery algorithm needs to be low latency, that means it needs to return results fast. This is because many users will only have the app open for a short amount of time.
- not publicly connectable - there is a good chance that most resource restricted devices are not publicly connectable. see more here.
Now let’s look at not publicly connectable in a bit more detail:
The way discv5 works, nodes are added into a DHT once they have an ENR that contains their IP. This is easy for most computers and servers to achieve, however for mobile phones this can be a little harder. Firstly because of the amount of round-trips it takes to achieve, and then the amount of time this IP would be valid for. This depends completely on the communication ISP.
So let’s look at how a node would be able to discover its IP to then be able to participate in the DHT. Thankfully, discv5 already has an in protocol method for us to do this. The flow would look as follows:
- Send
PINGmessage to a peer - Receive
PONGmessage with my current IP - Update IP and sign an
ENRrecord - Begin participating in the DHT
So this is a pretty simple process and works, however what we need to consider is how often a mobile phones IP address changes and what effect this has on the DHT, how many stale records will there be.
Mobile Phones and Cellular Data
So let’s look into cellular data, how telcos work for mobile phones and why this means that they may not be publicly connectable.
NAT
Let’s say node A sends a PING message to node B. B now knows its IP address and sends it back to A. C discovers A in the DHT and wants to send a packet to connect to A, there is no guarantee that A will be available to C on the same port it was available to B as. NAT traversal and UDP hole punching is notoriously difficult on cellular networks, this is because 3/4G networks use symmetric NAT.
“Ordinary UDP hole punching works with Port-restricted cone NAT, but it does not work with Symmetric NAT because ordinary UDP hole punching is based on the presumption that the user’s public port number (their port number of origin of outgoing UDP packets from the perspective of other computers outside their local network) and their public IP address (their ip address of origin of outgoing UDP packets from the perspective of computers outside their local network) do not change with subsequent connections made from the same local socket bound to the same private (internal) port on the host machine.” [2]
This is a problem, it means that most of our mobile nodes will not be able to participate in the DHT both ways if they using cellular data. This means a lot of nodes may be leeches.
An issue to track this has been opened, see details.
Participating vs Not-Participating
For a node to be participating in the DHT and it to be more efficient than just querying other participating nodes, it would probably be better to be online for a significant amount of time. If it is not, depending on the implementation a lot of revalidation of all stored peers would need to be done in a very short period of time.
Something clearly not possible with our restrictions, therefore it makes no sense to be fully participating in the DHT rather than just doing lookups. Node’s that run the DHT try to find the nodes closest to them to build their neighbours list, where as the lookup can be used to find any node anywhere which is an important distinction.
This was discussed with @kdeme, and he agrees.
This is also a tough one to test, in the simple testing scenario where we have 100 nodes and that is it, it would probably be more efficient cause we can just store all those nodes in a local database. However for this test we would need to take realistic network churn into consideration along with the windows of offlineness to determine how useful the stored list would be after a certain amount of time, versus just querying a few known available nodes.
Models
It makes sense to look at the calculations in our notebook under bandwidth required to participate in the DHT. Although these numbers are inaccurate due to the discussed windows in the previous section. They give a clear indication of consumption but should be taken with a grain of salt as this heavily depends on client implementation.
When we compare data from both theoretical models of the bandwidth required to participate and that required to simply lookup we see that the former clearly consumes more outbound and inbound bandwidth.
For rough numbers, if we have a network of 100 nodes and do a lookup to find a single node we use around 5.668 KB of inbound and outbound bandwidth. However, when we run a discv5 node, for an hour with a 60 second update interval we use 170.04 KB in bandwidth (if we maintain 1 peer throughout this period). Of course resource restricted devices would not run this long, however the amount of FINDNODE calls and NODE responses they must do far outweighs that of simple lookups when running as a fullnode.
Finding a peer or capability
In this section we will highlight the efficiency of finding a peer within discv5 and its various strategies. There are 3 methods by which we can find a peer, firstly we can look for a specific node, we can look for a node that advertises a certain capability in its ENR or we can look for a node that is within a given topic table.
Specific Node
Finding a specific peer in Kademlia based networks is pretty efficient, the theoretical numbers point to roughly O(log n) amount of lookups required for n number of nodes. Our simulation has proven that this is the case, for 100 nodes we were averaging between 2-3 lookups to find a specific peer. Assuming that each lookup has a latency of 100 milliseconds, it would require roughly 2-300 milliseconds until a peer is found (not accounting for CPU time etc).
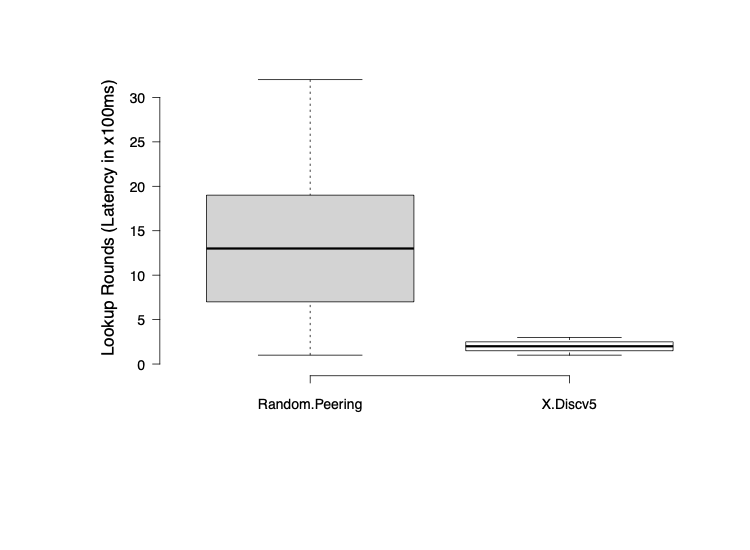
The above graph depicts this result in comparison to a network of randomly grouped nodes, providing an unstructured network. We see that a Kademlia network that is 10 minutes old as the one used in the test clearly outperforms a less organized network.
As we can see by the calculations in our notebook the bandwidth for simple lookups is also quite manageable. Making it an efficient method for Mobile nodes to participate in the DHT.
Capability Based
Capability based peer finding is nice because it allows us to potentially reduce bandwidth by not requiring a handshake to establish which capabilities a peer supports. This means that instead of connecting to every node to see if it is a mailserver for example, we simply filter for nodes that are only mailservers and then ask them if they really are still mailservers*. Having a simple capability discovery method would allow us to avoid handshakes to discover these details and rely soley on the discovery protocol. So let’s look at how this can be achieved in discv5.
*The check will become important once Waku embraces more adaptive nodes.
ENR
Searching for a node with a specific field in its ENR depends solely on the amount of nodes that have that characteristic. If we have one node with that characteristic, we can assume that the lookup efficiency is worse than that of simply looking up a node, O(log n). We assume worse due to the fact that we do not know the exact distance of the node we are trying to find, only the capability and these are not indexed. However, it is important to note that this may be different as queries may not be able to use the real distance a node is at because we do not know the full target ID rather than just a characteristic.
Given that we have multiple nodes, and assuming equal distribution. Say 5 out of 100 nodes, there is a low chance that we can effectively find these nodes. Simulation numbers point to an average of 1 lookup required when the distribution is 5 in 100, however this doesn’t tell us much due to the small size of the network. Scaling the network in the simulation would be possible with more dedicated hardware.
When looking at the calculations on the probability of finding a specific node with an ENR, we see that the larger our set of nodes get the more important a indexed table of capabilities becomes. Assuming we have ethereum like numbers with thousands of nodes and only around 0.1-1% nodes being a specific capability, the likelihood of finding a specific capability in the first lookup reduces drastically.
We can again look at the bandwidth for simple lookups, and conclude that although this is probably not most effective manner, and may be even less effective than looking for a single peer depending on the distribution. This is because we cannot accurately query due to us not knowing the real distance of targets.
Topic Tables
Now let’s get to the most important feature of discv5, topic tables.
Topic Tables in theory work the way finding nodes work, in order to first find a node which advertises a specific topic, you must find a node which contains advertisements for that topic. That is wholly dependent on the topic radius. One could naively say that this is also a O(log n) operation, where N is the amount of total nodes in the network. However this is uncertain due to the radius at which this advertisements are distributed.
This however, would mean that in a large environment, finding nodes with characteristics remains a O(log n) lookup, which would not be the case if we are randomly searching every node for nodes that contain some characteristic.
There is still a lot left unanswered in the discv5 specification related to topics. For example, topic radius estimation is broken, and there currently is no fix.
Routing Table sizes
Let’s look at the size of the routing tables for discv5. Discv5 uses k = 16, this means that a node stores a maximum of 16 * 256 = 4096 nodes in their routing table. This means that theoretically in a network of less than 4096 nodes every lookup will require exactly 1 hop.
Due to the fact that nim-eth uses a split-bucket approach, this assumption would accurate. This is also the case for go-ethereum’s discv5 implementation. This means that in a long-lived network, lookups should return the target node after exactly 1 hop, drastically reducing the latency.
However, as we can see by Dmitry Shmatko’s calculations, it is unlikely that a node will ever have peers closer than 239. Assuming those buckets are full it is exactly 272 nodes. However, this is also unlikely.
Summary
So now that we’ve looked at discv5 in detail. Let’s look at some of the blocker issues to continue our research.
-
NAT on Cellular Data
It is uncertain what the current state of NAT traversal is on cellular data, we need to find out what NAT schemes LTE networks use and if UDP hole punching is even possible on them. -
Topic Tables
We were unable to test topic tables in a simulation as they were not yet implemented in nim. Additionally there are still some open discussions about them that need to be resolved.
Conclusion
Hopefully this document gave you an overview of discv5 and some of the theoretical numbers associated. It should help in formulating a decision on whether the protocol is necessary or not. It will most definitely solve certain properties for us such as being censorship resistant. If this is the only property we want to achieve however, we may get the same properties out of something like dns based discovery over https. The problem there is there is centralization around who creates the records. There is probably some trade-off at a certain node count where it becomes worthwhile to invest heavily into discv5.
Acknowledgements
Thanks to all these people for reading drafts and helping out, in no particular order:
- Oskar Thoren
- Dmitry Shmatko
- Kim De Mey
- Core Petty