We know we’ve got a problem
Status is a decentralised project with centralised solutions. Proper decentralisation is a hard problem to solve. This post doesn’t solve any of it.
Recap
Dependence
Status nodes need to be able to send transaction data to and receive state data from the Ethereum network. Status nodes need to be super light because the devices Status node run on are expected to be very resource limited. This means that a Status node needs to rely on a trusted node to relay its transaction data and state query data.
Currently Infura is the solution. Infura sell us access to trustable node endpoints, and in return for convenience we give up our independence.
Light nodes don’t fix it … Yet
I know what you’re thinking, why don’t we just implement light node functionality? That’s a thing right? It is a thing but it doesn’t solve our problem, currently all light node systems basically boil down to a server / client relationship. One node has a fully synced state and a has a connection to Ethereum network peers (a full node), and the light node trusts the full node to send data.
The only way to make light nodes a truly scalable option is to develop incentivisation mechanisms to encourage and reward good actors and deter and punish bad actors. This is hard, we can discuss it in another post about “state data for sale”. Simply Infura is state data for sale along with transaction propagation for sale, where only Infura gets paid. There’s always a price for data and someone always has to pay the price.
The thing I actually wanted to talk about
Basically we need functionality beyond what Infura offers and we want to be independent of Infura, and a truly decentralised solution is not yet here.
What other solution could possibly solve our problem?
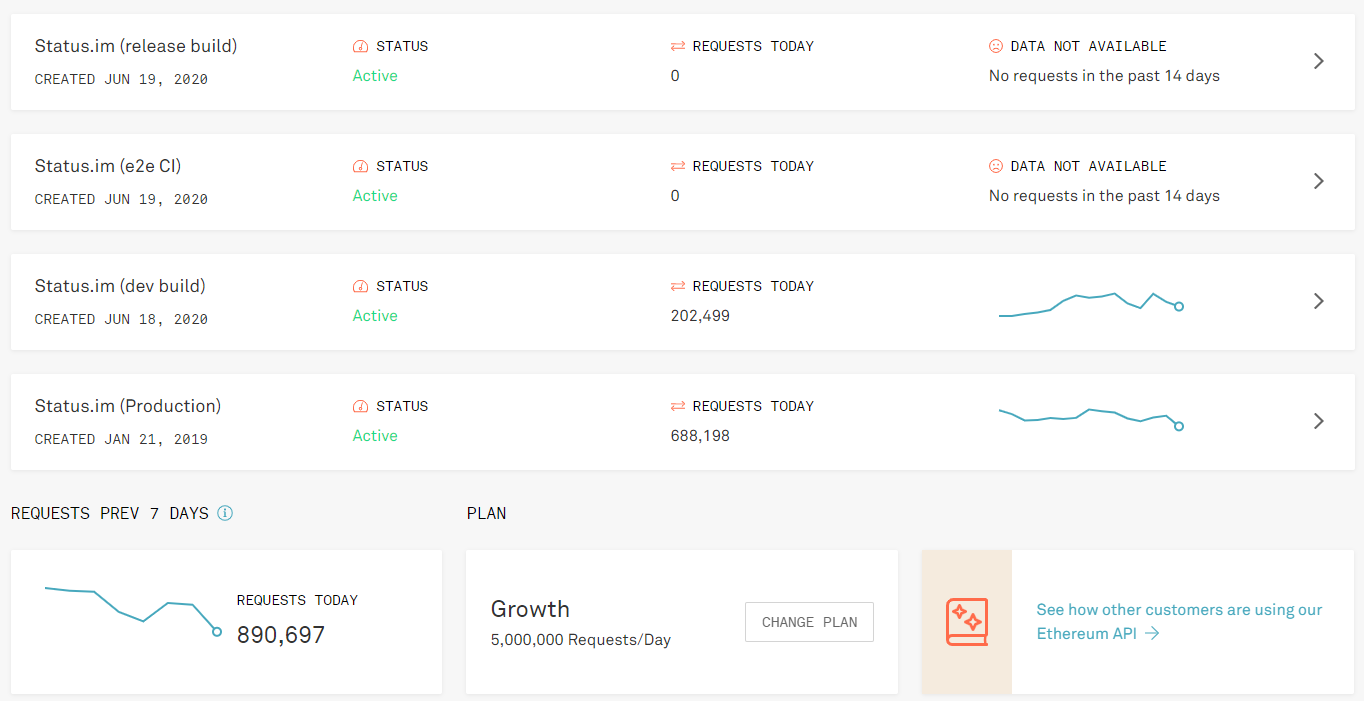
![]() Status managed Ethereum nodes
Status managed Ethereum nodes ![]()
This is probably old news to most of you, but the needs are still there. I made a picture to demonstrate the functionality for a pending transaction context, but the basic idea applies here.
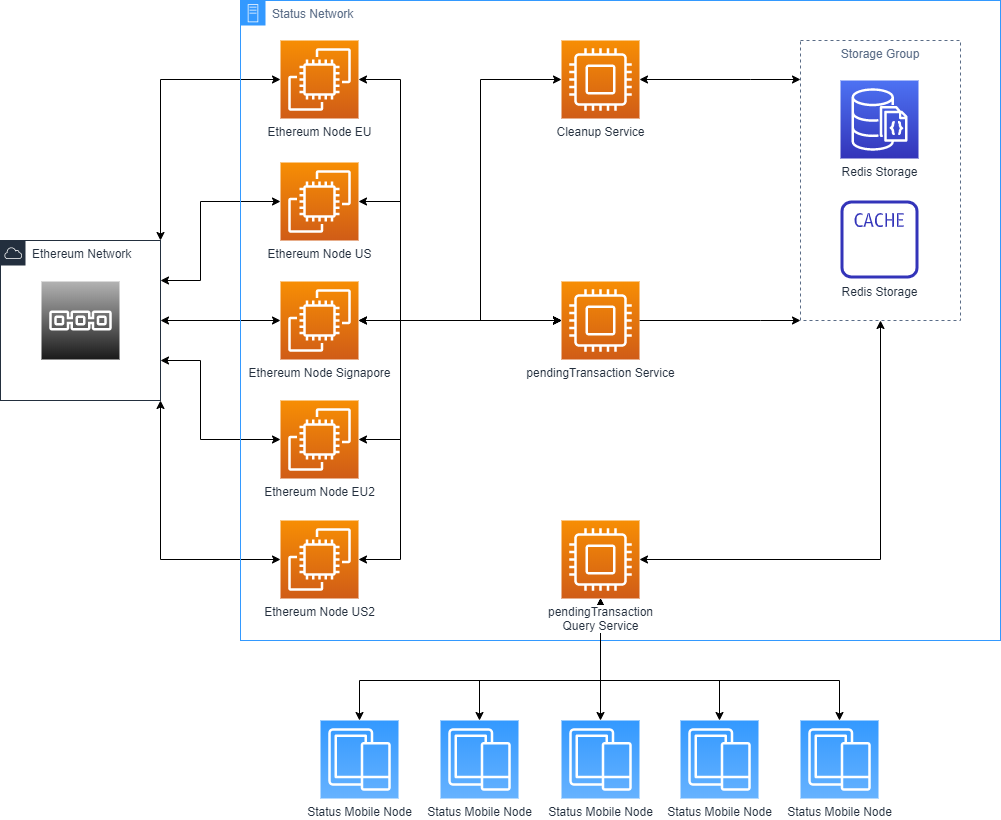
After speaking with @jakubgs he very helpfully provided initial costing for this kind of set up Infra Costs for Pending Transactions Experiment - CodiMD . And we’ve estimated that an in house solution would cost $800 in monthly infra costs.
FYI the server costs are not a blocker here, following from a conversion @jarradhope has highlighted
The $800 monthly infra costs aren’t really an issue nor is the approach of creating an infura alternative, the real issue in terms of cost is who is going to build it, maintain it and how long will it take. These were questions we raised last time during a strategy sync and I didn’t get an answer on it. It’s difficult to justify a new hire to build and maintain this. Last time we discussed this both Jakub and Corey were maxed out in terms of workload. How are things now?
So the main blockers are, with my weak:
- Who will build the solution?
- I can write the software for this, most of work is connecting raw nodes up to Redis and caching queries.
- Who will maintain the solution?
- Probably Jakub… But I’m sure he’ll have an opinion on that
- How long with building the solution take?
- I don’t know how long the full solution would take. I believe that it would take about 2 weeks to implement a basic first stage, for querying pending transactions.
- Will the team need a new hire?
- I don’t know, more input is needed.
Purely economically I expect that if cost of implementation + cost of maintenance <= Infura rental and implementation can be achieved in a reasonable time frame in house will be “a go”, if not probably means no in house.
Help needed
I need help answering the above blocker questions. Also I am look for opinions on my proposed roll out for the in house solution:
- Implement a light experimental solution for handling only ephemeral pending transaction data.
- This reduces cost on maintaining state and syncing nodes, keeps usage almost entirely in memory
- Implement a production solution for handling only ephemeral pending transaction data.
- This solves a current UX issue, where users expect to see incoming pending transactions
- Revisit the impacts and cost after pending tx have been:
- implemented experimentally
- Probably after 2 weeks
- implemented in production
- Probably after 1 month, in version 1.5
- again after 2 months.
- implemented experimentally
- Get more concrete estimations on engineer costs for a full Infura replacement
- Possibly this needs to be done before the experimental stage
- Identify the migration strategy (from Infura usage to in house)
- Implement nodes with full sync and state
- Implement most common RPC queries
- Implement automated processes for
- New node syncing
- Node version upgrades
- Node recovery
- Implement remaining RPC queries
- Implement truly decentralised light node functionality
- Retire in house node infra