Introduction
We want Status to be decentralized and censorship-resistant. Thus we must design our systems to work in offline environments, as well as for mesh settings.
Right now messaging is relying on 3rd party services like mail servers. They fulfill a role, relaying messages between nodes that aren’t online at the same time, but it is fragile. The system should work without it.
Data sync layer
By introducing a data sync layer in our protocol, we can improve on this. It decouples message sync state from transport and message content logic. It thus gives us more freedom going forward:
- to swap out Whisper as a transport privacy protocol
- build various communication mechanisms on top of this data sync layer
All a data sync layer cares about is keeping track of the state of messages. The above layers, like 1:1 chat or Tribute to Talk, then uses this sync protocol. The main idea is that each node is self-sufficient and equal in a true peer-to-peer fashion. They keep track of everything they know, including what they think other nodes know.
Rough protocol stack
| Layer | Purpose | Example |
|-------------------|---------------------------------|-----------------------|
| Sync Clients | End user functionality | 1:1, 1:N, TtT, Public |
| Data Sync | Syncing data/state | BSP |
| Secure Transport | Confidentiality, PFS, etc | Status PFS spec |
| Transport Privacy | Metadata protection | Whisper, PSS, Mixnet |
| P2P Overlay | Overlay routing, NAT traversal | devp2p, libp2p |
Transport/network layer below. There’s also a key agreement/exchange protocol.
Specific proposal
Introduce Bramble Synchronization Protocol (BSP) into the Status app. This acts as a in-between layer between Whisper and 1:1/group/public chat.
BSP doesn’t know what a valid message is, or what the relationship between messages is. That’s dealt with by data sync clients.
How does syncing work?
A device stores synchronization data for each message and each peer. This includes information such as: if a peer is holding a message, if ACK is required, when a message was last sent, etc.
Peers synchronize data by exchanging records. A record contains a header along with a payload.
The header includes protocol version and record type. A record type is things like:
- ACK (list of messages to be ACKed)
- MESSAGE (group id/sync scope, timestamp and message body)
- OFFER (offer to share some messages)
- REQUEST (list of message ids desired).
It doesn’t concern itself with what is in the message body, as that’s a data sync client concern.
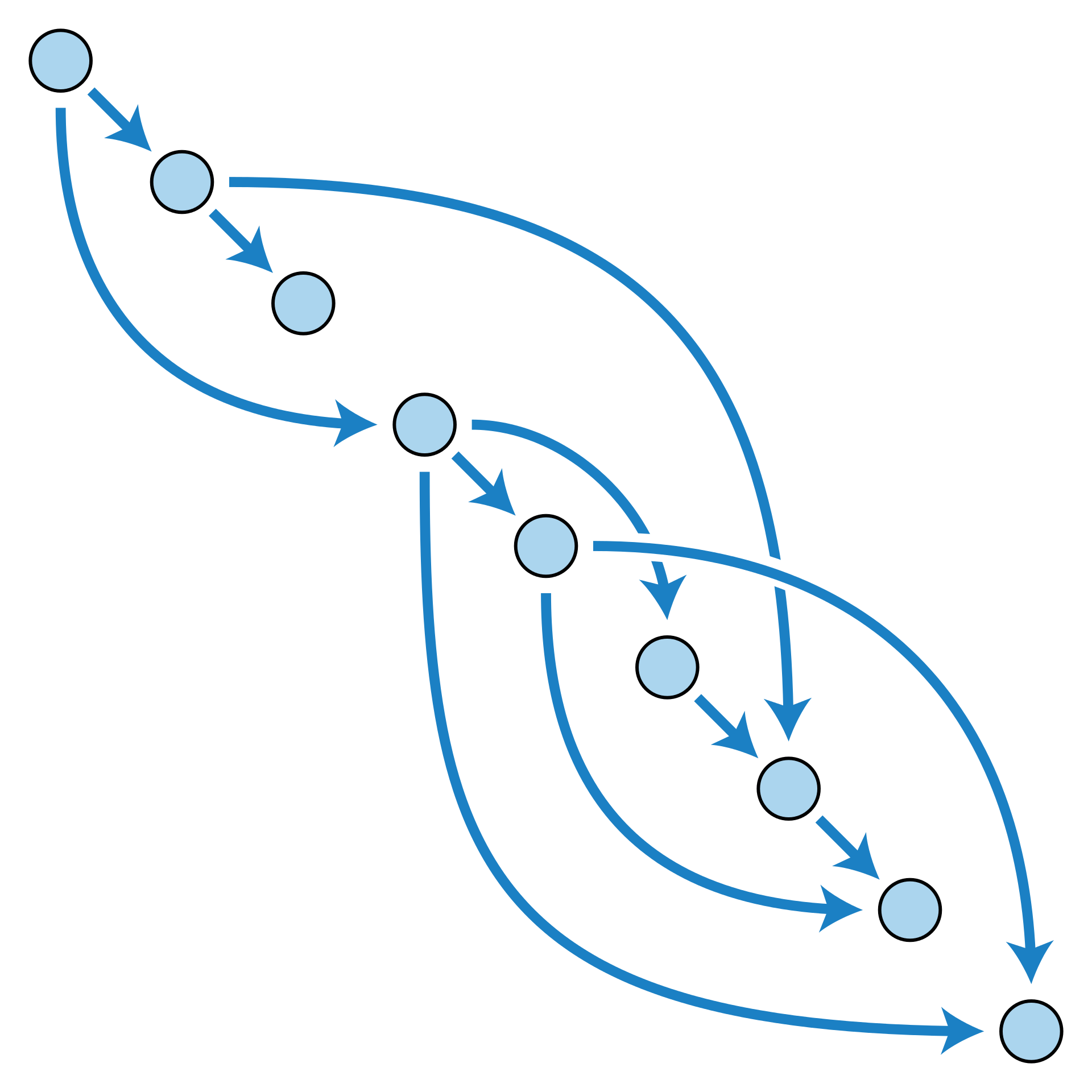
Message graph
A message is only delivered once all its dependencies have been delivered. This ensures a consistent view of messages. This means each message must have some information about “parent”/message dependencies. Exactly how this is provided is up to the specific data sync client.
This provides for casual consistency. Using topological sort, the user is presented with a consistent view. Since there’s no single source of truth in a p2p system, this is done with partial information. How this is rendered is up to the end client.
What would this mean for data sync clients?
Ideally this written as a specification in e.g. protobuf. This ensures multiple end clients can implement it and be compatible. Another way to think of this is as a form extensions. E.g. one end user client might only care about 1:1 chat or public chat, and ignore all the other mechanisms.
This requires some logic for what is inside a message and how you share. Each message needs to keep track of its parent messages, aka its dependencies.
Examples:
This is relevant for e.g.: Tribute to Talk, Hamburger Chats, Public Visibility Stake, Spam prevention etc.
Briefly on why BSP in particular
- Supports similar use cases
- Is actually used and reasonably specified
- Doesn’t have anything immediately incompatible with us
The main alternative would be something homegrown. This reasoning might be incorrect if:
- there’s a better, more well-designed alternative out there somewhere
- there’s something undesirable in BSP that would warrant our own spec (at this layer)
Briefly on network incentivization
This section isn’t yet fleshed out, but merits a mention.
Since this abstraction provides information about messages ACKed and clients can choose who to offer message, this can work similarly to Bitorrent’s economic abstraction layer. Exactly how this information is leveraged is outside of the scope of this post, but it’s worth pointing out.
Tangential considerations
Some things that may or may not be worth considering at this layer.
This doesn’t preclude the use of mailservers. Synchronization frequency etc can be titrated as well.
- Whisper signature key in messages and implications for messages being agnostic
- How to deal with long public chats with a lot of message dependencies
- UX(R): How to render threads in group/public chat to accurately depict state
- Using topological sort to get a canonical representation of past events for all end users.
– A la git merge of two branches (or not? what does this mean for casual consistency?) - Group chat different encryption algorithm (non-pairwise)
- Privacy preservation implications for underlying layers
- [cammellos]: bandwidth usage & offline/asynchronous messaging performance (i.e how reliable is retrieving a message chain when devices are often offline, with spurts of online activity, mobile), as those needs to be tested with a potentially much larger audience than briar’s use case, as briar seems to be more focused on close proximity interactions.
Further reading
- Log based comms: Status.app
- BSP: protocols/BSP.md · master · briar / briar-spec · GitLab
- Briar Client examples Home · Wiki · briar / briar · GitLab
Summary and next step
The introduction of a data sync layer simplifies the protocol design. It also gives us more options to do interesting stuff on top of and at the bottom of it. It is a good fit for true p2p and delay-tolerant/mesh networks due to it not making too many assumptions. Assumptions such as: messages being received, or relying on a 3rd party to sync messages.
Next steps
- Protobuf specification
- PoC for 1:1 chat
Additionally, this above work should be phrased as research and specification and documented as part of swarm framework. Either as part of Protocol Engineering Swarm or as part of Core/Data Sync.
Thoughts and feedback welcome!