tldr: current estimate for daily active users supported by version:
- beta: 100 DAU
- v1: 1k DAU
- v1.1 (waku only): 10k DAU (up to x10 with deployment hotfixes)
- v1.2 (waku+dns): 100k DAU (can optionally be folded into v1.1)
Assuming 10 concurrent users = 100 DAU. Estimate uncertainty increases for each order of magnitude until real-world data is observed.
This post summarizes our current understanding of how many users a network running the Waku protocol can support. Specifically in the context of the Status chat app.
As far as we know right now, there is one immediate bottleneck, a very likely bottleneck after that, and a third bottleneck that is still conjecture but not unlikely to appear. We go through them in order.
It is important to note that when we talk about users here we are talking about concurrent (within a two minute time frame, say) users. We use similar assumptions as are done in the Waku scalability model (https://vac.dev/fixing-whisper-with-waku). As a heuristic, we can convert concurrent users to daily active users by multiplying by 10 (online time ~2h/day average with no specific time bias).
Bottleneck 1 - Receive bandwidth for end user clients (aka ‘Fixing Whisper with Waku’)
This is the main focus of Waku. The best model we have for understanding this is
the model outlined in this post. There are also user reports.
Baseline
According to the model, at ~1000 users this starts to get into unacceptable territory. According to user reports for previous versions, it happens even at the <100 users stage. If you are in a lot of chats this bottleneck becomes apparent even sooner.
Improvement
For Waku, this should be fine up to ~100k+ users. There are also likely modifications we can make (partition topic logic) to get this even higher. However, this stops being the bottleneck earlier than that, see the next point.
Supporting evidence:
- Scalability model
- Simulation for nim-eth with basic topologies and random traffic that supports model
Unknowns:
- Not a full scale simulation in a real network with ~10k+ nodes
- Not battle tested tested in the real-world yet (e.g. mobilephones)
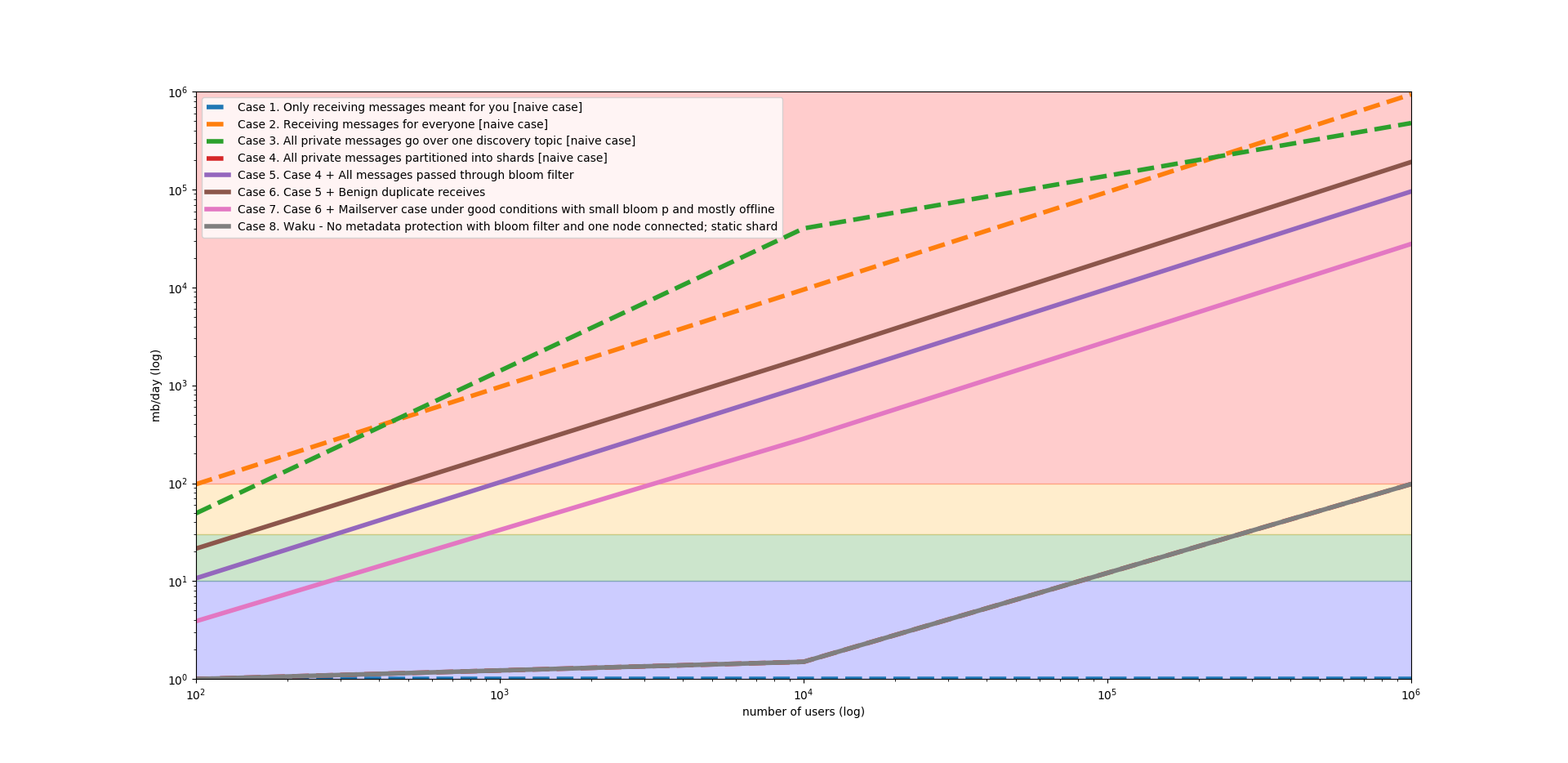
Case 7 approximates app v1, Case 8 is using Waku
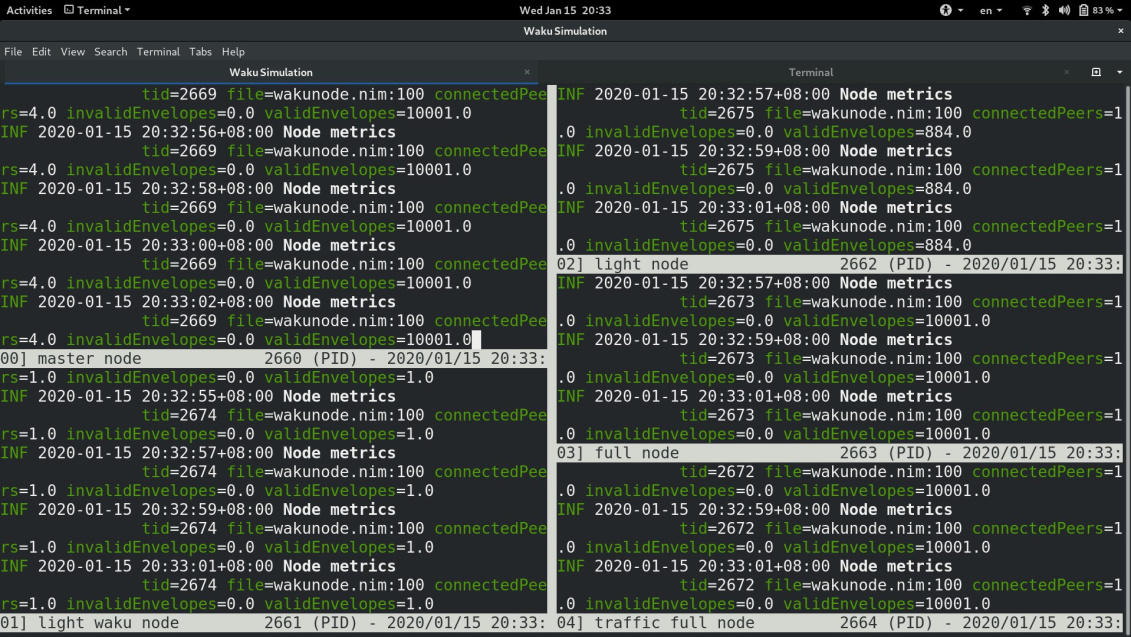
Simulation in Nimbus, notice envelope count for waku vs light node vs full nodes.
Bottleneck 2 - Nodes and cluster capacity (aka ‘DNS based node discovery’)
Baseline
When an end user connects to a node, it does this primarily through a cluster operated by Status Gmbh. While there is a discovery mechanism to dynamically connect to more nodes, it is currently not general or reliable enough to work for proper resource sharing. More on the current Discovery mechanism here and current issues with it.
In v1 the Status app hardcodes on the order of ~10 nodes across various regions. While we can spin up new nodes, we have to assume the worst case where users either don’t upgrade, or discovery mechanism isn’t robust enough. Each such node has about ~150 free connections. This means we currently have a bottleneck on the order of ~1000 concurrent users.
Mitigations
This issue is less fundamental than the first one in that it is easier to mitigate with quick fixes. For example: users running their own nodes, users using custom nodes, adding more nodes to our cluster and distributing them (e.g. through hotfixes).
Supporting evidence:
- General scaling and server capacity observations, familiar problem
Unknowns:
- Propensity for people to run or use custom nodes
- Reliability of current discovery mechanism (assuming none)
- User behavior in case of hotfix to increase cluster capacity
Improvement
A more fundamental solution is to fix the discovery mechanism. The first step is to add DNS based discovery capability (EIP-1459), which will later likely be extend to something more dynamic (Proper Discovery v5, or similar, with capabilities and optimized for resource restricted devices - longer time research effort). See more details and discussion here. Once this is deployed, there is no reason to believe another realistic bottleneck will be hit here, not accounting for the cost of running nodes. Instead, we are likely to hit another bottleneck.
Supporting evidence:
- DNS well known and scales extremely well
- Supports subtrees for arbitrary node inclusion
Unknowns:
- Specific solution not battle-tested (afaik)
- DNS Core integration time (current estimate ~1w)
Bottleneck 3 - Full node traffic (aka ‘the routing / partition problem’)
This is where we are getting into more speculation territory. Assuming we have passed the two previous bottlenecks, the next one is likely going to be traffic between full nodes. While Waku largely solves end client / light node bandwidth usage, full nodes relaying traffic are taking up the rest of the burden.
There is currently no efficient routing, and Waku in its inital iteration doesn’t change this fundamental property of Whisper for full nodes. As a mental model, we can imagine that every node receives every single live message in the network (in fact, depending on the exact network topology, this number will be multiplied by some duplication factor).
With a lifetime of ~2 minutes per message, what is the likely resource constraint on that node? As far as we know, it is going to be memory-bound - how many messages can a node keep in its memory before things start to break down? A simple test here is to put a bunch of a messages in a Waku queue and look at memory usage. Running Waku node simulation with ~10k concurrent envelopes I see ~10mb memory usage. Assuming a node has ~1gb of memory, that’d allow for 100k concurrent users sending 10 messages in two minutes. This is for status-nim, it might look different for status-go. Even then, this is very speculative and there might be other resource constraints that we hit on before that (CPU, IO perf for mailserver, etc). To make this a slightly more conservative estimate before we have more real-world data, let’s call this 10k concurrent / 100k active.
Supporting evidence:
- Rough consensus based on discussion and general intuition
- Hacky quick test (not reliable, also mismatch with production nodes)
Unknowns:
- What the actual bottleneck will be here (memory, io, etc)
- real-world perf: status-go, dockerized, networked, etc
Mitigation
Monitor and profile cluster nodes in production and do necessary tweaks (DB index, instance type, fix memory leaks, etc) to squeeze the best out of each node.
There might be some load balancing things we can do here too.
Supporting evidence:
- Traditional techniques, well known problem
- Can be done without updating app (claimed IPs)
Unknowns:
- What the actual bottleneck will be here
- What the limits for individual nodes are
Improvement
The fundamental issue is that each node does too much work. The proper solution is to split up work, for example through more efficient routing (DHT like, etc). More on this to come at a later stage. This is a longer term research priority for Vac.
Summary and current plan
This is our current understanding of things to the best of our knowledge. it is likely wrong in several areas. The real test is real-world production usage. If you know something that would change any of the above, please comment below ![]()
Plan:
- The main thing left for Waku is core integration and deployment, to be done after v1
- DNS based discovery spec is still under review but expected to be merged soon, at which point it is a matter of core integration for v1.2 or optionally v1.1
- Research is ongoing for the third bottleneck, more updates to come here later from Vac